Data Through the Modern AI System: The New ML Data Stack
Over the past year, large language models (LLMs) have been a hot topic in the world of AI, captivating both experts and non-experts. Terms like “Transformers,” “Nvidia H200s,” “prompt engineering,” and “hallucinations” are becoming common buzzwords—a testament to the shifting paradigms in AI development.
A big sign of their impact is that last year, 40% of code produced by Github Copilot users was unedited LLM output, indicating a growing confidence and trust in the end product produced by LLMs.
But, making the most of these advanced AI tools involves more than just slapping a user-friendly interface on top of LLM APIs and expecting magic to happen. Companies’ operational and data moats cannot be actioned with this shallow approach; simply doing that won’t unlock their full potential. Instead, a paradigmatic shift in how we collect, process, and leverage data is required.
Leaders in AI adoption need to aggregate and contextualize their existing data assets to supercharge this next generation of products. Techniques like retrieval augmented generation are boosting this, allowing AI to understand and use information in more sophisticated ways. This evolution moves away from old-school data and model management, enabling the development of nuanced, smarter AI applications that understand context better and can be developed faster.
However, these advances come with their own set of challenges. Language models are becoming more complex, larger, and more expensive to use. These massive, often third-party, models are opaque, leading to hurdles in terms of observability and monitoring. LLMs’ structural complexity, expansive parameter spaces, and closed-source operators make it harder for developers and data scientists to diagnose issues or predict model behavior.
These challenges and opportunities necessitate a reevaluation of the ML data stack. We need to rethink our data tools and methods to address these issues. This includes finding new ways to organize data, track where data and models come from, and closely monitor how models are working.
Diving into the shifting stacks below, it’s evident that emerging solutions and categories are just the beginning.
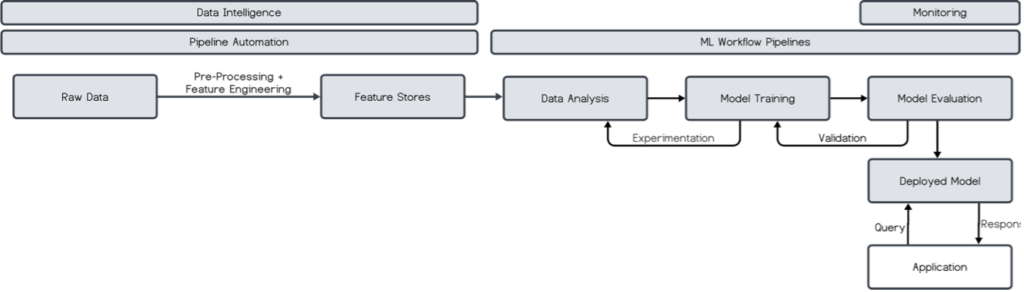
In traditional machine learning, the data preparation process is highly structured and requires significant preprocessing, demanding the expertise of specialists for system design and construction. Data engineering bleeds into feature engineering as a mixture of experts create and maintain ETL definitions, data catalogs, orchestration frameworks, and the underlying compute. The data produced by this system is used to develop and later run machine learning models.
The creation of these models leans heavily on the expertise of data scientists and engineers, who use their statistical knowledge and technical skills to choose the right architectures. These are developed, trained, and evaluated in-house using the traditional data science stacks. On-prem and cloud deployments are, again, first-party. Additionally, the outputs of traditional ML models are generally predictable and well-defined, facilitating straightforward evaluation of their performance and relevance. Traditional ML revolves around complex, in-house, cross-functional processes with reliable and interpretable outcomes.
What’s New
Unlike other machine intelligence advances, LLMs radically impact the data stack beyond development and deployment. New norms are emerging, and different stakeholders are controlling the creation and usage of models. This shift is crucial because it challenges traditional roles and introduces a collaborative approach to managing and leveraging data, indicating a significant transformation in how businesses and technology strategize around AI.
LLMs Are Expensive To Create From Scratch
The creation of LLMs isn’t for the faint of heart. It requires significant computational resources, specialized labor, and vast datasets, all of which cost a lot of money, putting it beyond most organizations’ reach.
That said, creating a language model is similar to making any traditional machine learning model. We start with a lot of raw text data, which is then cleaned up to ensure it’s consistent and reliable. Next, this text is broken down into smaller pieces called tokens, which are groups of 1 to 5 letters each. This approach makes it easier to work with than predicting each letter one at a time.
A large neural network is then trained to predict the next token in a sequence. Given the large scale (billions of parameters and trillions of tokens), this process is parallelized, distributed, and accelerated with GPUs. Traditional back propagation generates a foundational model’s weights.
Once a foundational model is created, copies can be created, which then undergo additional training. This helps to further refine a broad and capable model to perform a specific set of tasks using domain-specific datasets. This fine-tuning of the model can help specify response tone, terminology, and preferences for given queries.
Managed Models Are Becoming The Norm
Once a model has been trained (and optionally fine-tuned), it has two different outputs. The first, next token prediction, drives ChatGPT and other text output applications. The second output, an embedding model, gives a view into the internal state of the model given some text.
Given the cost and complexity of creating and managing these models, most organizations cannot afford to build them in-house. Similar to cloud providers before, closed and open-source providers API-ify these prediction and embedding models. OpenAI, Anthropic, and Google’s Gemini Ultra lead the closed-source race. Open-source alternatives lag six to twelve months in capabilities. Open-source models such as LLaMA 2, hosted by platforms like HuggingFace, Replicate, and Mistral, enable organizations to manage their own instances

LLMs Handle Unstructured Data Well
Unstructured data has historically required tailored structuring before being usable in down-stream analysis and model building. An LLM’s ability to consume raw text during both training and inference significantly reduces the need for deep structuring of data. While traditional models require complex feature engineering, LLM’s emergent capabilities allow for more robust processing of raw inputs.
Feature engineering still holds a place in the LLM data stack. Specifically, mathematical operations aren’t well defined in today’s LLMs. Instead these pre-computed features are better provided via context to LLMs.
LLMs Can Be Given Inference-Time Context
Even with fine-tuning, LLMs still lack insight into user-specific and time-sensitive data, like a user’s shopping history or today’s NASDAQ price price. Solutions like retrieval-augmented generation (RAG) solve for this. RAG is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge to supplement the LLM’s internal representation of information.
Unlike fine-tuning, RAG doesn’t require further model training. Instead, the additional context is provided directly in the prompt. Moreover, RAG better incorporates additional context when generating compared to fine-tuning, though fine-tuning still excels in shaping and controlling task specific behavior (e.g. setting response tone or output format).
Finding the right context to provide is an outstanding problem. Current solutions rely on embeddings and vector databases.
Finding Relevant Context is Complicated
Embeddings are semantic representations of data that foundational models create (see OpenAI embeddings). They provide a way to group and perform math on language. A well-known example of the types of problems that can be solved with vector representations:
King – Man + Woman = Queen
Going a step beyond addition and subtraction, vector databases (VDBs) give a way to index, store, and search over embeddings. A simple example with strings instead of embeddings:
embedding_search(”dog”) = [”labrador”, “pet”, “puppy”]
Further, some platforms provide solutions for chunking large documents into relevant sub-sections to be searched and provided as context. It is important to note that embedding alone doesn’t solve the problem of finding relevant context. Depending on the problem, a broader ([”cat”, “hot dog”, “Snoop Dogg”]) or narrower ( [”labrador”, “bulldog”, “shih tzu”]) set of embeddings returned might be more relevant.
Pinecone, Chroma, and Qdrant have accumulated early traction in the VDB race, but preexisting platforms like MongoDB, Supabase, and Postgres have now adopted similar functionality.
Embedding management platforms help organizations systematically turn their data into semantic representations. Some solutions, like Symbl AI, specialize in embedding creation and management. Qwak and Pathway take broader approaches extending traditional ML and ETL workflows to the generative space.
LLM Inference Is Getting More Complex
In the early days of generative AI, find-and-replace templates for prompts were sufficient for simple chat apps. As the number of prompts, RAG frameworks, model providers, and decision flows grow, so does the complexity.
Agent platforms like LangChain attempt to manage and tame this complexity through orchestration. Anthropic’s new Claude 3 model adds first-class orchestration capabilities. They plan and execute complex multi-step tasks across several resources (foundation models, VDBs, web-resources, etc). Prompt engineering platforms specifically focus on prompt creation, evaluation, and testing across different prompt and RAG frameworks. These prompt engineering tool tend to be developer oriented, but technical PMs are starting to contribute as friction is reduced.
Monitoring and analytics on Generative AI systems is especially important given the non-determinism, opaque internals, and huge space of possible inputs and outputs. These tasks don’t resemble traditional monitoring problems, and instead have more dimensions to measure and optimize across.
LLMs Produce Black Box Predictions
The opaque nature of LLMs’ predictions presents a unique set of challenges in terms of understanding, testing, and monitoring their operations. Addressing these challenges, observability and evaluation tools are emerging as critical components in the toolkit of developers and data scientists (see Aporia, Arize AI or Context AI).
Real-time monitoring solutions, such as those offered by Weights & Biases, provide insights into performance metrics like latency and cost, enabling more efficient management of AI systems. Meanwhile, platforms like Patronus AI and Fiddler are at the forefront of evaluating semantic aspects of AI outputs, such as toxicity and correctness. These tools enhance transparency and trust in AI applications but also pave the way for more responsible and effective use of technology.
The New LLM Data Flow
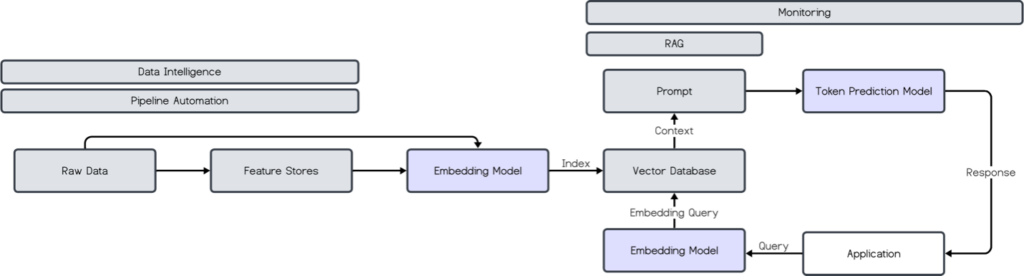
The Players

What’s Next
Advanced Embedding Management
Meaningful generative AI adoption hinges on the ability to enable data for these systems. As companies strive for greater visibility, understanding, and capability in handling their semantically indexed data, the demand for platforms that offer sophisticated context retrieval capabilities will surge. These platforms are set to go beyond mere similarity searches, facilitating complex use cases that unlock the full potential of data assets. Furthermore, these platforms will enable real-time, user-level context management to serve the next generation of AI-native apps.
Capturing and Effectively Using Unstructured Data
The advent of new generative AI data flows transform the way companies perceive and utilize unstructured data. On the supply-side, processing with generative systems allows deeper meaning to be extracted easier. At the same time, down stream demand for data is increasing to enable fine-tuning and RAG use cases. Streams of data that were once overlooked or deemed too complex to capture will become invaluable sources of insight. These developments are particularly exciting for sectors that are rich in unstructured data but have lacked the tools to benefit from it.
Automation of Data Engineering Tasks
As AI becomes more common in different fields, making data engineering tasks easier through automation is becoming increasingly important. First-time adopters of AI models are in dire need of tools that simplify the process.
Automated solutions can also reduce development time and costs for existing data stacks. This trend points to a future where data engineering tasks are increasingly streamlined through automation, enabling data teams to focus on higher-level strategy and innovation. The systematic conversion of data into searchable, model-ready context will accelerate the adoption of AI and enhance the scalability and effectiveness of data initiatives across the board.
What We’re Saying:
In conclusion, the advent and integration of LLMs within the AI paradigm signify a pivotal transformation in data handling, processing efficiencies, and the overarching methodologies of machine learning applications. This discourse has illuminated the critical facets of LLM deployment—from the nuanced handling of unstructured data to the orchestration of complex inference mechanisms and the challenges posed by model transparency and data governance.
The shift towards a more dynamic, efficient, and context-aware AI ecosystem underscores the imperative for a paradigmatic shift in both technological infrastructure and data strategy. Challenges associated with these advancements, such as the need for advanced embedding management, automation of data engineering tasks, and the effective utilization of unstructured data, offer a glimpse into the future directions of AI research and application.
We are super excited about the developments in the data infrastructure to serve modern AI systems. If you’re building in this space, we want to hear from you.